



파이썬 셀레니움(sellenium)을 이용한 웹크롤링 방법은?
2021. 8. 17. 17:06
파이썬으로 크롤링을 할 때 가장 처음 접하는 패키지는 urllib이다. urllib을 이용해서 손쉽게 원하는 정보를 크롤링할 수 있지만, 벽에 부딪힐 때가 있다. 자바스크립트로 동적으로 생성되는 페이지를 크롤링하는 경우이다. 이 때 urllib패키지를 이용하면, 자바스크립트가 적용되기 저의 소스를 받아오기 때문에 원하는 정보를 크롤링할 수가 없다.
오늘은 sellenium을 이용해서 웹크롤링하는 방법에 대해서 알아보도록 하겠다.

셀레니움(sellenium)은 웹테스트를 위한 자동화 도구이다. 그래서 코드로 웹브라우저를 조정할 수 있다. 페이지의 소스도 볼 수 있기 때문에, 웹크롤링에도 사용할 수 있다. 웹페이지의 여러 요소들을 직접 동작시킬 수 있기 때문에, urllib보다 더 강력하게 웹크롤링을 할 수 있다.
셀레니움을 사용하기 위해서는 각 브라우저에 맞는 웹드라이버를 설치해야 한다. 필자는 크롬 브라우저를 많이 사용해서 크롬 웹드라이버를 설치했다. 웹드라이버는 크롬 브라우저 버전에 맞는 것으로 설치해야 한다. 크롬 브라우저 버전 정보는 [도움말] 메뉴에서 확인할 수 있다. 웹드라이버 설치 주소는 아래 링크를 참조하기 바란다.
( 참조: 웹드라이버 다운로드 페이지 바로 가기 )
셀레니움(sellenium)을 설치하고, selenium패키지의 webdriver모듈을 import 한다. 아래와 같이 코드를 입력하면 크롬 브라우저가 실행된다. 고스트 모드로 하면 웹브라우저를 백그라운드에서 실행시켜서 할 수도 있다. 하지만, 브라우저를 직접 보는 게 편해 필자는 그냥 브라우저를 띄워놓고 작업한다.
from selenium import webdriver
browser = webdriver.Chrome('크롬드라이버 위치 입력')
원하는 주소로 이동하기 위해서 get함수를 호출한다. 그러면 원하는 주소로 이동할 수 있다.
browser.get("url 주소 입력")
이동한 상태에서 객체의 page_source변수를 호출하면 html소스를 불러올 수 있다. 자바스크립트로 작성된 페이지도 동작이 끝나 후의 소스를 가져온다. 따라서, 동적으로 변하는 웹페이지도 크롤링할 수 있다.
html = browser.page_source
셀레니움(sellenium)에서는 별도로 html파싱을 하지 않아도 된다. 파이참에서 "."을 누르면, 사용할 수 있는 함수 리스트를 볼 수 있다. find로 시작하는 함수명이 보인다. 모두 클래스 이름, id, 태그 등 필요한 정보를 추출할 수 있는 함수들이다.
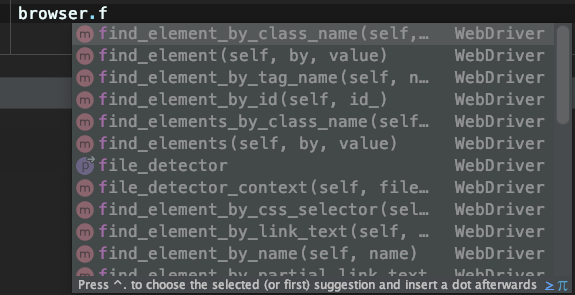
Xpath도 사용할 수 있어, 태그를 지정하기 어려울 때 편리하다. Xpath는 HTML의 주소를 의미한다. 특정 위치의 태그를 손쉽게 선택할 수 있다. XPath의 사용방법은 다음 포스팅에서 자세히 알아보도록 하겠다.
오늘은 이렇게 파이썬 셀레니움(sellenium)을 이용한 웹크롤링 방법에 대해서 알아보았다. 웹의 요소들을 직접 컨트롤할 수 있고, Xpath도 사용할 수 있어 익숙해지면 urllib패키지보다 유용하다. 특히 자바스크립트로 동적으로 생성하는 페이지는 sellenium으로만 할 수 있어, 알아둘 필요가 있다.
| 파이참(pycharm)에서 주석으로 항목 관리하기 (0) | 2021.08.20 |
|---|---|
| 파이썬 주석, 파이참(pycharm)으로 똑똑하게 활용하기 (2) | 2021.08.18 |
| 파이썬 조건문 if문 한 줄에 작성하는 방법은? (0) | 2021.08.17 |
| 파이썬 urllib패키지로 웹크롤링 하는 방법 알아보기! (0) | 2021.08.16 |
| 파이썬 if문, 파이참에서 쉽게 작성하기! (0) | 2021.08.15 |